HashTable Class
해싱(hashing) 메소드를 사용하는 연관 컨테이너입니다.
template <class IndexType, class ItemType>
class HashTable : public AssociativeContainer< IndexType, ItemType >
Template 파라미터
- IndexType
-
해시 테이블의 항목들에게 접근할 수 있는 인덱스(키)의 타입입니다.
- ItemType
-
해시테이블이 저장할 수 있는 항목들의 타입입니다.
멤버
생성자
내용 관리
내용 쿼리
| Enumerate |
해시테이블 항목들의 열거를 허용합니다.
|
| Begin |
해시테이블의 1번째 항목을 참조하는 반복자(iterator)를 리턴합니다.
|
| End |
해시테이블의 마지막 직전 항목을 참조하는 반복자(iterator)를 리턴합니다.
|
| EnumeratePairs |
해시테이블 내용의 열거를 허용합니다.
|
| BeginPairs |
해시테이블의 1번째 인덱스-항목 쌍을 참조하는 반복자(iterator)를 리턴합니다.
|
| EndPairs |
해시테이블의 마지막 직전 인덱스-항목 쌍을 참조하는 반복자(iterator)를 리턴합니다.
|
성능 튜닝
Public 타입
설명
HashTable은 해싱(hashing) 메소드를 사용하여 매우 빨리 항목들에 접근할 수 있는 AssociativeContainer 구현입니다.
인덱스(키) 타입은 다음 형태 중 하나로 외부 해시 값 생성자(generator) 함수를 제공해야 합니다:
ULong GenerateHashValue (const IndexType& from);
ULong GenerateHashValue (IndexType from);
이 함수는 파라미터로부터 정수를 생성해야 합니다.
이것은 결정적이고, 빠르고, 분산이 좋아야 합니다. (가능한 많이 서로 다른 파라미터들이 서로 다른 해시 값들을 산출해야 함)
미리 정의된 생성자(generator) 함수들이 있습니다. 여기에는 빌트-인 정수 타입(char, short, int, long 및 각각의 unsigned 타입), C 문자열(const char*), 포인터, GS::UniString이 있습니다.
또한 헬퍼(helper) 함수도 있습니다.
ULong GenerateBinaryHashValue (const IndexType& from);
이것은 지정된 타입의 바이너리 레이아웃을 기반으로 한 해시 값들을 생성하는 데 사용할 수 있습니다.
게다가 인덱스(키) 타입은 비교 연산자(==, !=)들을 가져야 합니다. (내부 또는 외부)
항목 접근, 삽입, 제거 비용은 상수에 매우 가깝습니다.
인덱스-항목 쌍들을 해시 리스트들 안에 저장합니다.
모든 인덱스는 생성된 해시 값의 modulo와 현재 해시 리스트들의 개수와 함께 취하여 해시 리스트를 결정합니다.
서로 다른 인덱스들은 동일한 해시 리스트에 포함될 수 있습니다.
해시 리스트 내부에서 비교 연산자들을 사용하여 값으로 인덱스들을 비교하여 원하는 인덱스를 찾기 위해 선형 검색을 수행합니다.
평균 탐색 요소는 해시 테이블의 일부 구성에서 기존 인덱스를 찾는 데 필요한 평균 비교 횟수로 정의됩니다.
결정된 해시 리스트에서 적어도 하나의 비교가 항상 수행되므로 최소 평균 탐색 요소는 1입니다.
평균 탐색 요소는 해시 리스트들의 인덱스 분포에 따라 달라집니다.
균등(uniform) 분포는 평균 탐색 요소를 감소시킬 것입니다.
새로운 인덱스-항목 쌍들이 해시 테이블에 들어가면, 평균 탐색 요소가 장기적으로 증가하고 성능이 저하됩니다.
사용자는 해시 테이블이 해시 리스트들의 수를 (약 2배) 증가시켜 평균 탐색 요소를 감소시키는 평균 채우기 요소에 대한 제한을 지정할 수 있습니다.
이것을 재해싱(rehashing)이라고 합니다.
채우기 요소는 해시테이블의 크기(저장된 인덱스-항목 쌍의 개수)와 해시 리스트들의 현재 개수의 비율로 정의합니다.
이것은 해시 테이블이 얼마나 많이 채워졌는지 보여줍니다.
재해싱해도 평균 탐색 요소가 감소하지 않는 나쁜 상황이 발생할 수도 있습니다. (아래의 사례 연구를 보십시오)
그러면 그것은 즉시 또 다른 재해싱을 유발하게 되고, 나쁜 상황에서는 전체 메모리가 소모될 때까지 다른 재해싱을 유발할 것입니다.
그러나 재해싱 후에는 채우기 요소가 확실히 감소합니다. (대략 기존의 절반 정도)
사용자는 재해싱을 고려해야 하는 최소 채우기 요소를 지정할 수 있습니다.
최소 채우기 요소는 연속 재해싱을 방지하고 작은 평균 탐색 요소를 지정할 때 특히 유용한 메모리 사용 효율을 제어합니다.
재해싱은 평균 채우기 요소 한계와 최소 채우기 요소를 모두 초과하는 경우에만 발생할 것입니다.
해시 리스트들 내부의 인덱스들의 순서 역시 제어할 수 있습니다.
검색 순서 최적화가 활성화되어 있는 경우 마지막으로 접근한 인덱스가 리스트 앞에 배치될 것입니다.
그 결과, 자주 사용되는 인덱스들이 리스트 앞에 근접하게 됩니다.
이것은 다른 인덱스보다 일부 인덱스에 훨씬 자주 접근할 때 유용할 수 있습니다.
이 최적화는 오버헤드가 거의 없지만 LRU (Last Recently Used) 전략은 대부분의 항목들을 주기적으로 접근하고 그 빈도 수가 비슷할 때 성능이 낮아질 수 있습니다.
재해싱하면 순서 변경이 일시적으로 중단된다는 것을 참고하십니다.
기본적으로 이 최적화는 비활성화되어 있습니다.
인덱스-항목 쌍들의 주소는 안정적이지 않습니다. 재해싱과 제거로 인해 변경될 수 있으므로 해시 테이블의 다음 변경 작업이 호출될 때까지만 항목들에 대한 참조들을 저장할 수 있습니다.
해시 테이블은 인덱스-항목 쌍들에게 중간 오버헤드를 부과합니다:
인덱스-항목 쌍 저장 셀의 총 비용은 인덱스와 항목 자체, 다음 셀에 대한 포인터, 해시 리스트들에 대한 포인터들이 포함된 해시 리스트 테이블로 인한 오버헤드를 포함합니다.
항목들은 기본 생성자와 복사 생성자, 할당 연산자를 가져야 합니다.
이외에도 비교 연산자(==와 !=)를 갖고 있다면, 값 종속적인 연산(예. ContainsValue 등) 역시 사용할 수 있게 됩니다.
인덱스들은 기본 생성자와 복사 생성자, 할당 연산자, 비교 연산자(==, !=), 그리고 외부 GenerateHashValue 함수를 가져야 합니다.
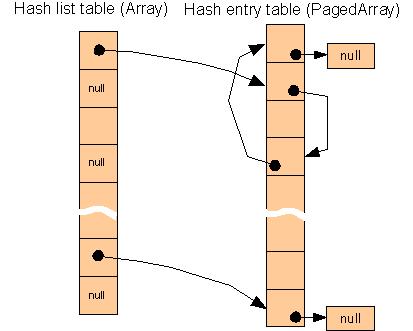
다음 그림은 HashTable의 내부 레이아웃을 보여줍니다.
선형 할당 전력을 이용하는 Array와 PagedArray로 구현되었습니다.
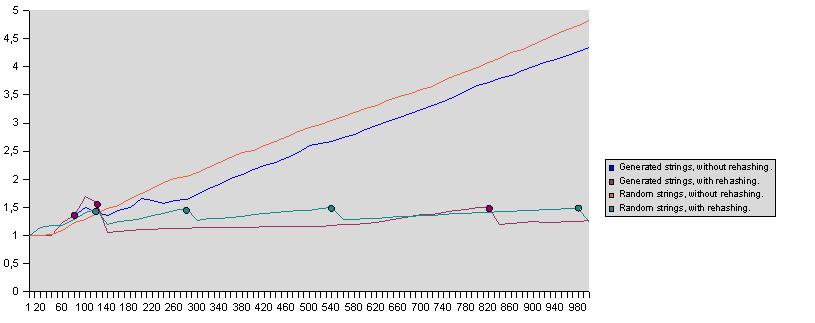
다음 다이어그램은 문자열 인덱스들을 갖는 해시 테이블 크기(저장된 인덱스-항목 쌍의 개수)의 함수에서 평균 탐색 요소의 적합성을 보여주는 사례 연구를 보여줍니다.
임의 문자열과 생성된 문자열("000000", "000001", ...), 그리고 각각 재해싱을 한 것과 재해싱을 하지 않은 것으로 시도했습니다.
4가지 사례를 산출했습니다.
재해싱을 사용했을 때 평균 탐색 요소 한계는 1.5이고 최소 채우기 요소는 0.5였습니다.
둥근 점들은 재해싱 지점들을 나타냅니다.
흥미로운 것은 생성된 문자열을 사용하여 첫 번째 재해싱을 했을 때 평균 탐색 요소가 증가했다는 점입니다. (나쁜 경우)
그러나 채우기 요소가 0.5 이하로 떨어졌으므로 다음 재해싱은 다소 늦게 이루어질 수 있었습니다.
한편, 나쁜 분포가 주로 새로운 인덱스들에 대하여 빈 해시 리스트들이 주로 사용되었기 때문에 평균 탐색 요소는 감소하였습니다. 이는 값 1의 많은 탐색 요소를 도입하였습니다.
2번째 재해싱 후 평균 탐색 요소는 천천히 부드럽게 증가했습니다.
3번째 재해싱은 문자열 경우의 3번째 재해싱 이후에 발생했습니다!
생성된 문자열 경우들의 평균 탐색 요소가 주로 랜덤 문자열 경우들의 평균 탐색 요소보다 낫다는 점도 흥미롭습니다.
이는 생성된 문자열들, 해시 값 생성기 함수, 해시 목록 테이블의 프라임 크기의 복잡한 결합 때문입니다.
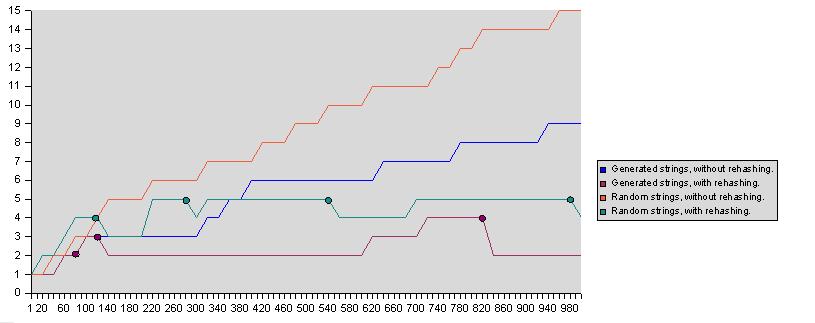
다음 다이어그램은 해시테이블 크기의 함수 안에서 최대 탐색 요소의 적합성을 보여줍니다:
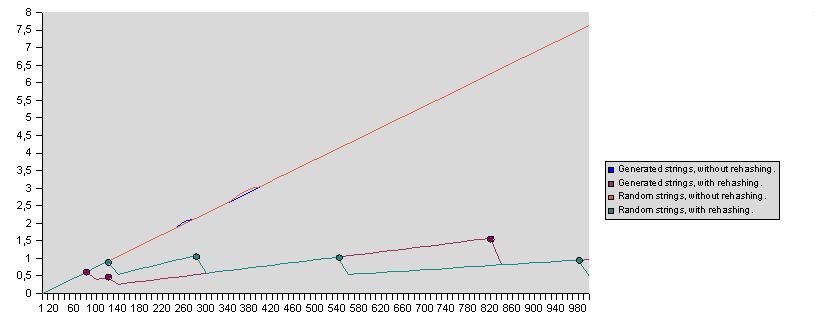
다음 다이어그램은 해시테이블 크기의 함수 안에서 채우기 요소의 적합성을 보여줍니다:
요구사항
네임스페이스: GS
헤더: HashTable.hpp